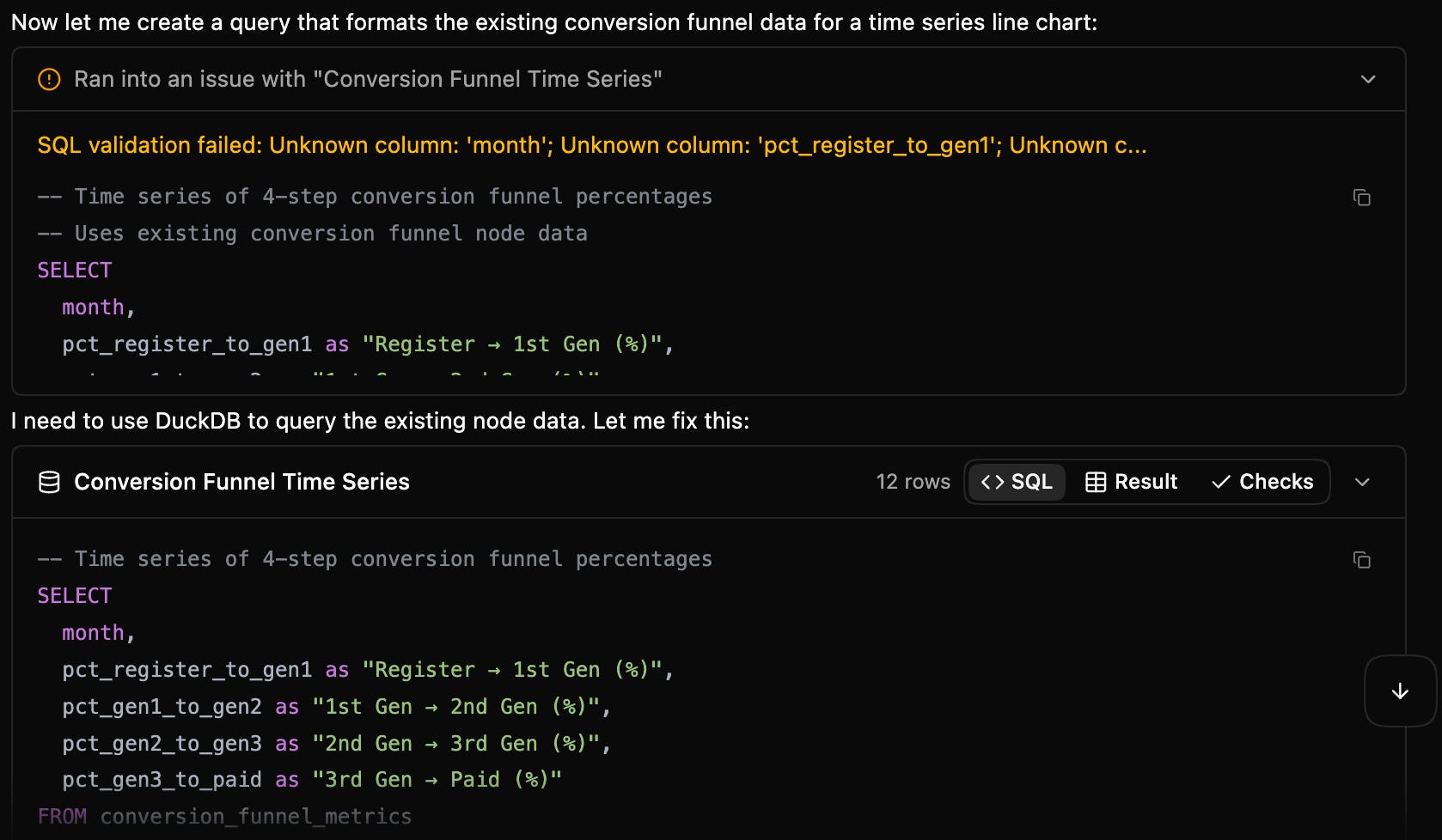
Why are LLMs so bad at SQL?
And what we should be doing for SQL instead

Claude Projects are basically persistent chat workspaces with uploaded knowledge and instructions, not a schema-aware SQL runtime. Because of that, you have to feed Claude real query examples and document schema quirks (e.g. use canonical_source, not source) and you get to leverage it as a Project across the whole team. This works in the same way a pretty good intern works; they observe your instructions very diligently in training so they can pattern-match off your examples, and they produce output that overfits to those examples. Until it doesn’t, and you run out of context because there are too many examples to curate.
What you actually want is a code-executable semantic graph that doesn’t waste context tokens. A query LSP (language server protocol) validates SQL code by programmatically parsing a SQL query for the syntax, joins, and table/column names against the actual database schema (called “linting” in eng speak). Rather than reasoning if the query makes sense, it runs through code checks before the SQL is run on the actual database. The code mapped the relationships between your tables, columns, and metrics encoded as structured knowledge, not a bunch of SQL files that the model has to reverse-engineer patterns from.
Note: An LSP is not the semantic graph itself; it’s a code runtime that can use a semantic graph or schema metadata as backing store. The semantics might live in your dbt models, metrics layer, and governance; the LSP is the runtime that surfaces that as errors, warnings, and completions.
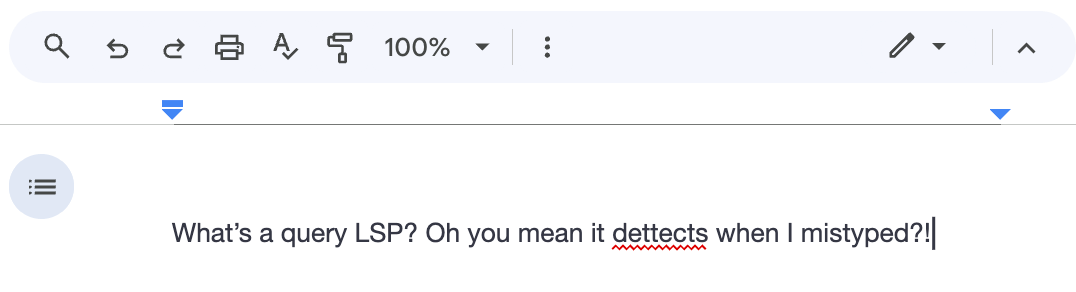
Running a query LSP is the metaphorical equivalent of Google docs red underlining spell + grammar-check.
What you also want is a system where fixing the underlying model (your ETL transformation, your semantic layer) automatically updates what the AI knows. dbt Labs recently published a piece on how they’re building an LSP into their Fusion engine as a background process that holds your entire dbt project in memory, understands your models and their relationships, and validates SQL in real time without ever hitting your warehouse. Other startups have built custom query LSPs like slateo.ai/query. Rather than manually documenting join relationships and column definitions in project instructions, it scans your dbt pipelines/ETL code directly and codifies the data model so that Claude self-corrects invalidated SQL.